My last post looked at web scraping using VBA, where I loaded a single page and extracted content.
In this post I'm looking at loading multiple pages from a site and getting the content I want from each page.
Let's say I want to get the latest Excel articles from the Office 365 blog
This is the first page of the site
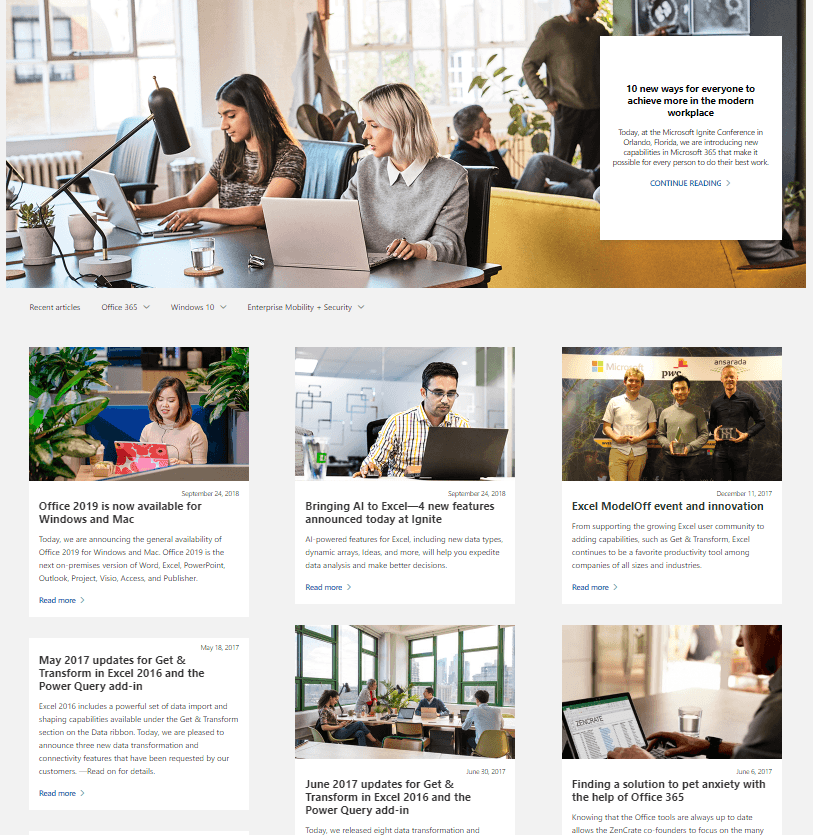
There's a header image followed by the blog posts. Some have an associated image, but all have a title linking to the main post, and a summary.
Below the posts there is navigation to access the next page or go direct to a particular page.
Download Sample Code
Download a copy of the example workbook with the code used in this post.
Enter your email address below to download the workbook.
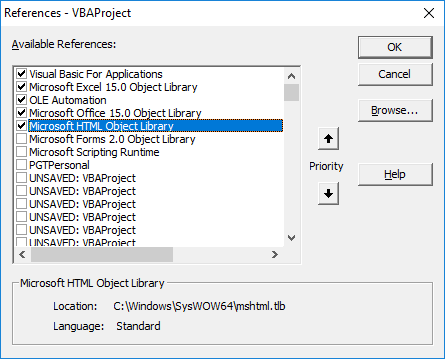
You need to set a reference to the HTML Object Library it in your VBA project before this code will work.
Open your VBA editor (the keyboard shortcut is ALT+F11) and with your workbook selected in the VBAProject window, go to Tools -> References.
Look for Microsoft HTML Object Library and check the box beside it. Then click OK.
How To Load Multiple Pages
By creating an instance of Internet Explorer from VBA, you can navigate to whatever URL you like.
Create IE Object

Navigate to a Page

To access multiple pages I need to find out what the URL structure is for each page.
The URL for the home page is https://www.microsoft.com/en-us/microsoft-365/blog/excel/
The URL for the 2nd page is https://www.microsoft.com/en-us/microsoft-365/blog/excel/page/2/ so to access a page you need to add /page/x/ to the end of the main URL, where x is the page number you want.
Knowing this URL structure it's now easy to write code to page through however many pages you want.
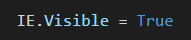
I've written the code so that IE is visible as it loads different pages. It's good to see it working so you know it's doing what it should.
If you want to hide IE, change True to False in this line.
What Are We Extracting From the Pages?
I want to get the post title, and the link to that post. To do this I need to be able to find them in the HTML code that makes up the page.
Right click on a post title and choose Inspect element - or whatever similar wording is your your browser's menu.
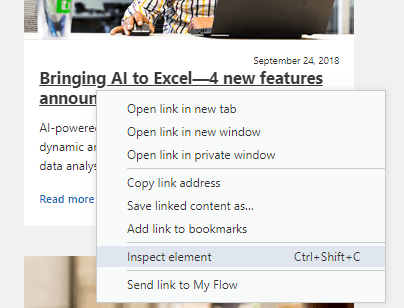
This will open your browser's inspection window and will highlight the element you want to inspect - the blog title.

I can see that the blog title is a H3 - a type of heading - with the CSS class "c-heading". This H3 heading contains the <a> link to the blog post itself.
Knowing this I can write my VBA to extract all H3 headings

and then look for those with the class "c-heading".

Then get the <a> link from inside that H3 heading.

Now I write this out to the sheet as a hyperlink, and loop through all the links doing the same thing.
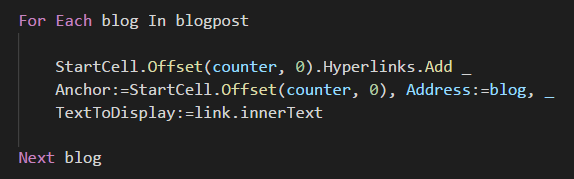
When I get to the last one I load the next page, and repeat the process.
Your sheet should now contain a list of hyperlinks to the blog posts.
Paging Content
Websites that have paged content should have a consistent structure for the URL's on each page, so it's just a case of finding that and then you can write your VBA to load each page.


Hi, thank you for this template. I was wondering whether it is possible to check if a specific text is on a webiste, if so then print found in the coloumn next to the URL in excel. I need to do so for 750++ Websites. Any idea how to do so?
Thank you!
Hi Tarek,
The short answer is yes this can be done. To give you a better answer I’d need to know what text you are looking for and a sample of websites where it is and isn’t found.
Please open a topic on the forum and supply all of this information and we can answer you there, with a sample workbook.
Regards
Phil
Thanks for posting this article about webscraping. I have a few questions. So here are the things I have:
A BOM list of parts (part description, part #, etc.) in spreadsheet form
Is it possible to create a VBA tool that looks at that BOM list by sub assembly and puts the BOM part information into a form, and have the VBA tool perform webscraping by finding spec information for each part online? i.e. There is a 8 input/output Turck communication block on the BOM. We want the tool to see that item and automatically do a web search on Turck’s website that looks for that specific part and a few desired specs of that part into a spreadsheet?
Have you ever created a VBA tool that pulls information from SAP?
Hi Alex,
This sounds like something that could be done. If you can post a qs on the forum and include your file we’ll take a look.
You might want to look at Power Query to get data from SAP.
Phil
Hi Philip,
I changed the number of pages of the said website to go through in the browser then obtained 687 articles in a total. In addition to the tactic of iterating over multiple pages of web data using power query this is the first time I found another approach by using VBA. Thank you very much for such an amazing and valuable gift.
You’re welcome Julian.
Same code if you want to scrape from Edge?
Hi Giorgio,
Edge does not support COM automation so can’t be accessed from VBA. IE is installed on all modern versions of Windows though so you should be able to use that.
Edge can be automated using WebDriver so if you really want to try that check this https://blogs.windows.com/msedgedev/2015/07/23/bringing-automated-testing-to-microsoft-edge-through-webdriver/
Regards
Phil