In this post I'm going to use the Text.Remove and Text.Select functions in PQ to extract characters from text strings.
I'll show you how to extract letters, either uppercase or lowercase, and a mixture of both, and how to extract numbers, and I'll show you a really cool way to remove a wide range of characters from strings.
I'm going to do this in Excel but you can use the same code in Power BI - just copy/paste the query code from the example file.
Watch the Video

Download Workbook
Enter your email address below to download the sample workbook.

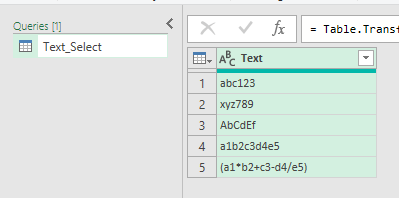
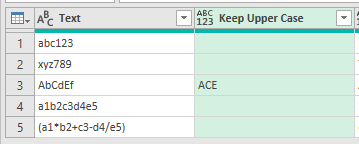
Starting with this table in Excel I've got a bunch of random text strings

Power Query Lists
I'm writing a lot about lists in this blog. If you need a refresher then please read Power Query Lists.
So first things first, open Power Query by clicking into the table, then from the Data section of the Ribbon click on From table/range.
Rename the query to Text_Select - you can't use a dot in the name so can't call it Text.Select
Extract Lower Case Letters
To extract all the lower case letters, add a new custom column
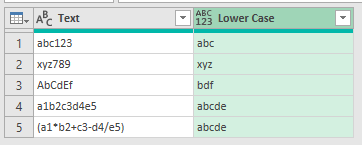
Call the column Lower Case
The code is Text.Select ( [Text], {"a".."z"} ) , the .. means create a list from the first char "a" to the last "z", and include all letters in between

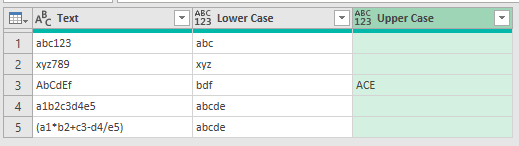
The contents of the new column look like this
OK that's pretty easy. You can probably guess how to extract the upper case letters.
TIP
Enter opening and closing pairs of brackets/braces at the same time : () , {} and []. Don't open them then type lots of code and get lost, forgetting how many you have to close again. It's easy to do if you are nesting functions or working with lists and records.
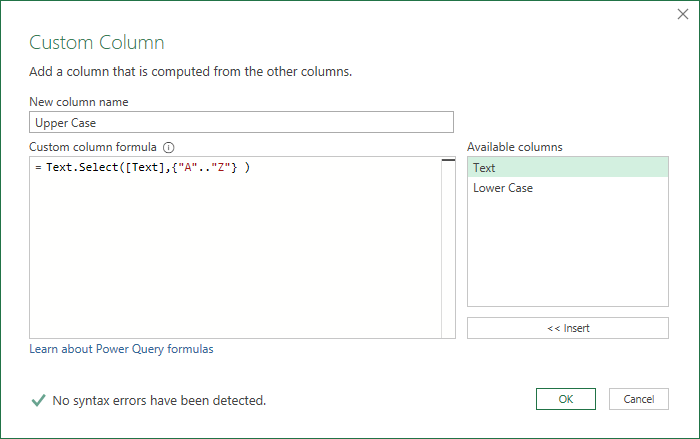
Extract Upper Case Letters
Create another custom column and call it Upper Case. The code is
Text.Select ( [Text], {"A".."Z"} )
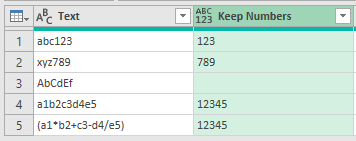
Extract Numbers
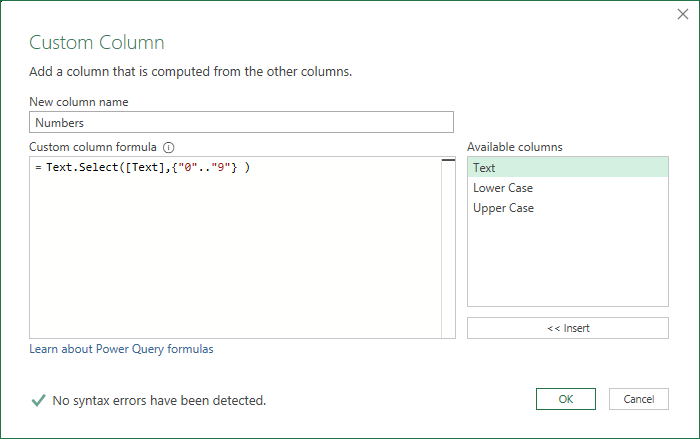
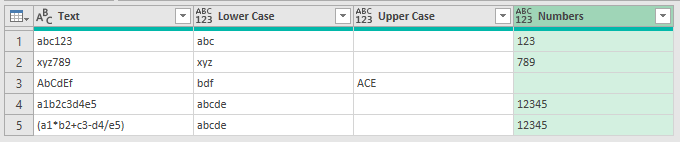
Extracting numbers follows the same pattern, create a custom column, call it Numbers, and the code is
Text.Select ( [Text], {"0".."9"} )
Extract Letters and Numbers
Extracting letters and numbers is a mix of the previous bits of code
We've already seen that to extract lower case letters we use a list define like this { "a".."z" }
So to also extract upper case letters and numbers you add the list definition used for each to give this
{ "a".."z", "A".."Z", "0".."9" }
Add a new custom column called Letters and Numbers, entering this code
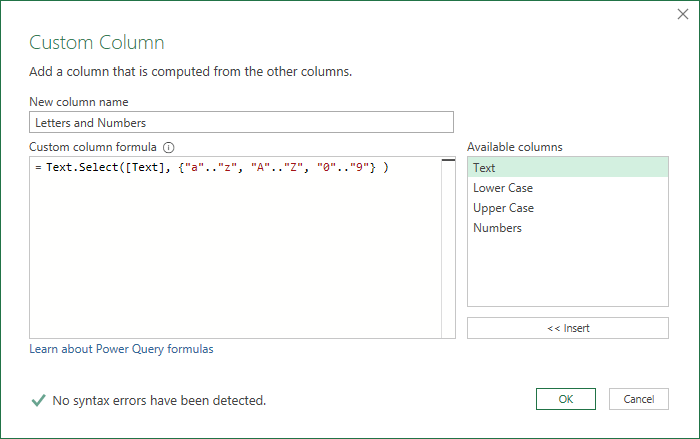
and the result this gives is

That's it for Text.Select let's move on to Text.Remove
Text.Remove
As its name suggests, Text.Remove removes text from a string. The syntax is similar to Text.Select, you supply the text string then a list of characters to remove.
Text.Remove requires you to specify what to remove. Whereas Text.Select only needs you to tell it what to keep.
That sounds obvious to say but sometimes you my not know exactly what characters will be in the string so Text.Remove can be less flexible to use - but there is a way around this which I'll show you.
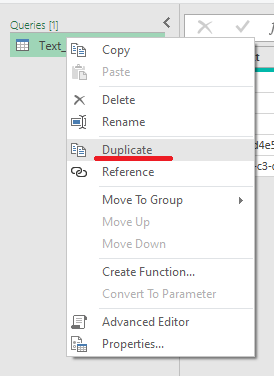
Let's duplicate the first query and rename it Text_Remove.
and Delete all these steps from here
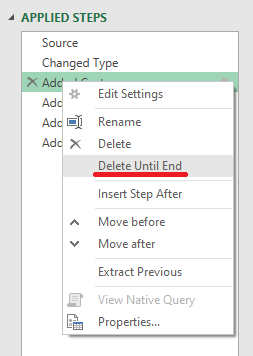
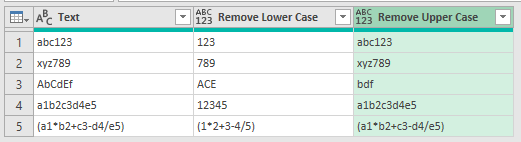
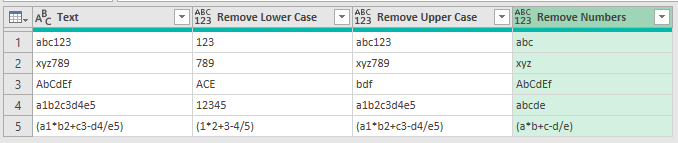
Remove Lower Case Letters
If you have a relatively simple string then using Text.Remove can be quite easy.
To remove lower case letters, create a new column and unsuprisingly the code is this
Text.Remove( [Text], { "a".."z" } )

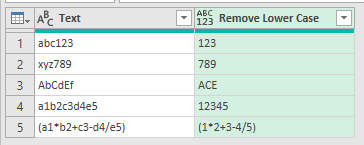
Remove Upper Case Letters
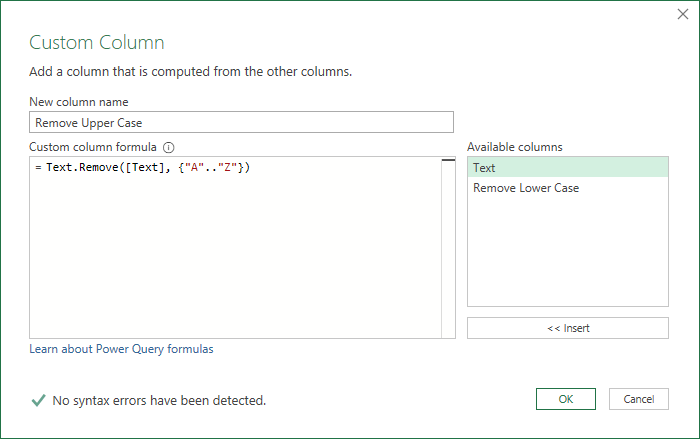
To remove upper case letters add a custom column and enter this code
Text.Remove( [Text], {"A".."Z"} )
Remove Numbers
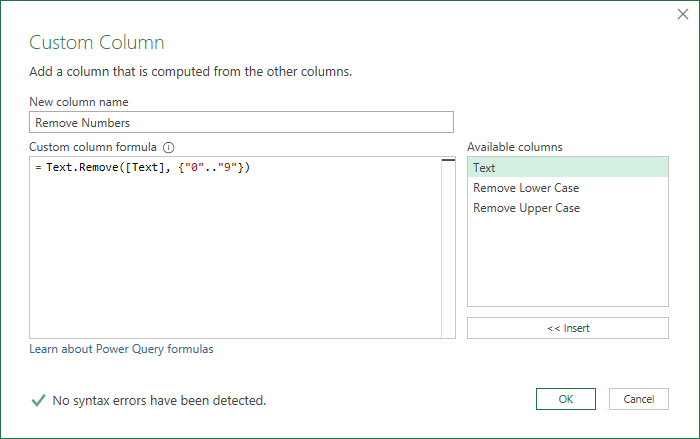
Add another custom column and use this code
Text.Remove( [Text], {"0".."9"} )
Remove Letters and Numbers
If you had some reason to remove al the letters and numbers from a string then this is the code to do that (add a custom column first)
Text.Remove( [Text], {"a".."z", "A".."Z", "0".."9"} )

The Drawback of Text.Remove
All of these examples are straightforward but the drawback with Text.Remove is that using it this way you have to know what's in the string to remove it and this isn't always the case in the real world.
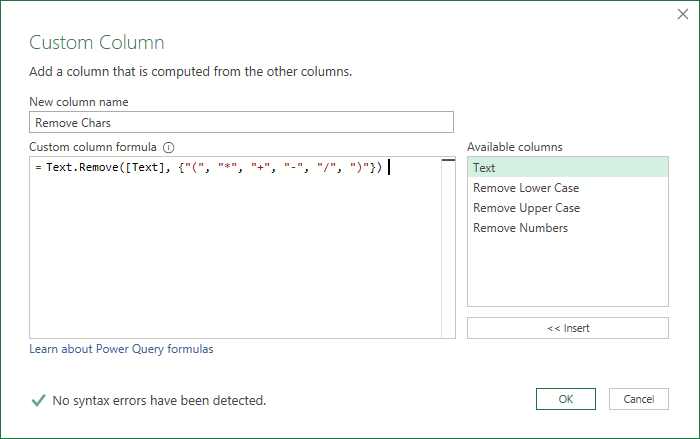
If you look at the text in row 5 of the Text column of my dummy data, it contains brackets/parentheses and lots of maths operators.
You could use this code to remove those characters, specifying each one individually
Text.Remove( [Text], { "(", "*", "+", "-", "/", ")" } )
But what if the string was even worse with lots of other characters, and more importantly, you didn't know what those characters were going to be?
Well here's where knowing what's going on under the hood of PQ helps.
It might seem obvious that when I create a list A..Z that I mean all the upper case letters from A to Z but what's actually happening in Power Query?
When you use the .. to create a list of sequential characters like A to Z what PQ is actually doing is using the character's Unicode value to construct the list.
Unicode is a technical standard for the consistent encoding, representation, and handling of text.
Looking at this Unicode character table you can see that A is represented by the decimal number 65 and Z is 90.
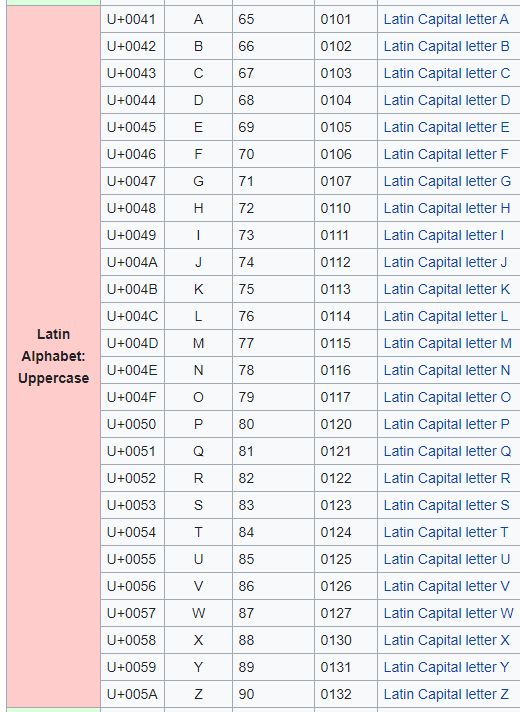
If you used the Character.ToNumber function it will return 65 for A and 90 for Z.
So the list specified by A..Z contains the characters specified by this Unicode table with decimal value 65 through to and including 90.
The key here is that the first character I specify, A, has a lower Unicode value than Z.
I can actually create a list with any characters as long as the starting char has a lower Unicode value than the ending character.
I'll show you another example.
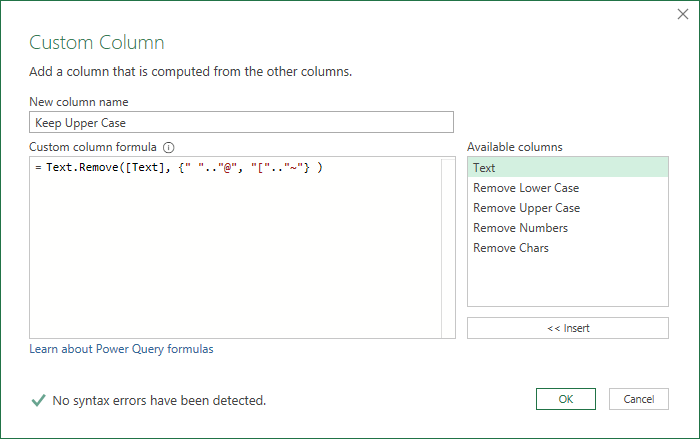
If I want to keep upper case letters in my string then I want to remove everything else.
Rather than creating one list for lower case letters and then another list for numbers and maybe several other separate chars that all need to be removed, using the Unicode table I can create a list that specifies every character to remove.
Starting with the space char " " (Decimal 32)
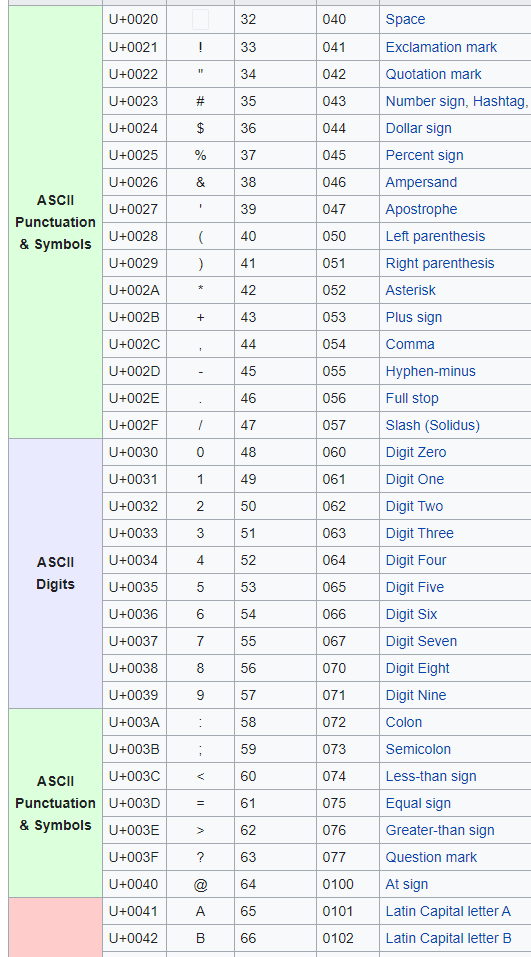
Looking down the table you can see that the last char before uppercase A is the @ so I can write " ".."@" and that means create a list of every character between space and @.
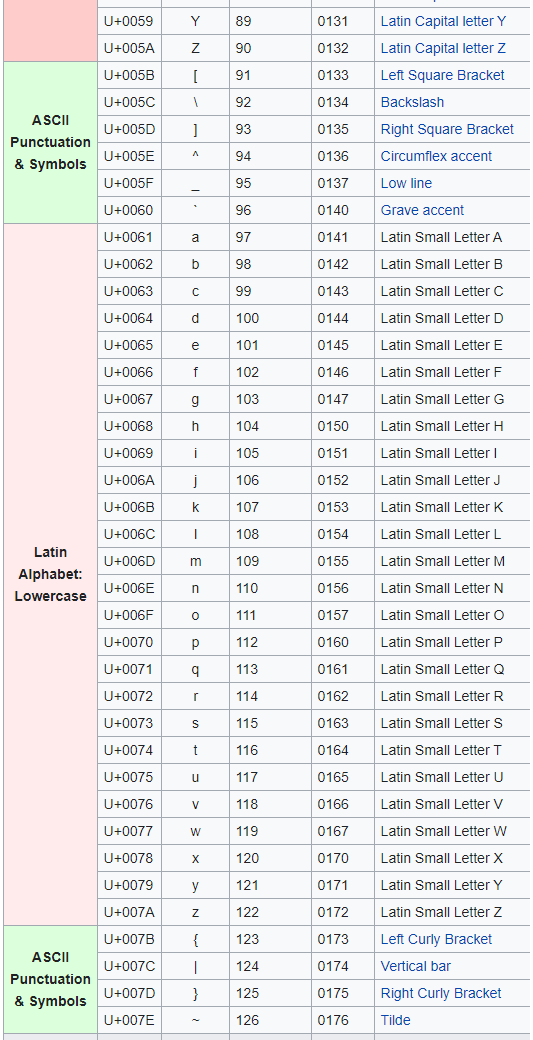
After Z is left square bracket and then the last character in this table is the tilde.
I can write my list of characters to remove as
Text.Remove( [Text], {" ".."@", "[".."~"} )
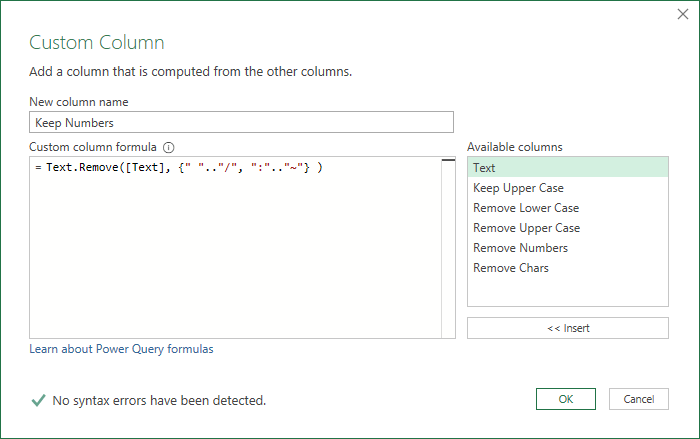
If I want to clean up the mess in row 5 and be left with just numbers my code would start creating a list with space again being the first character.
Checking the Unicode table, I want to go down to the slash (decimal 47)
Skip over the numbers, and start again with the first character after 9 which is the colon
Then go to the end which is the tilde character.
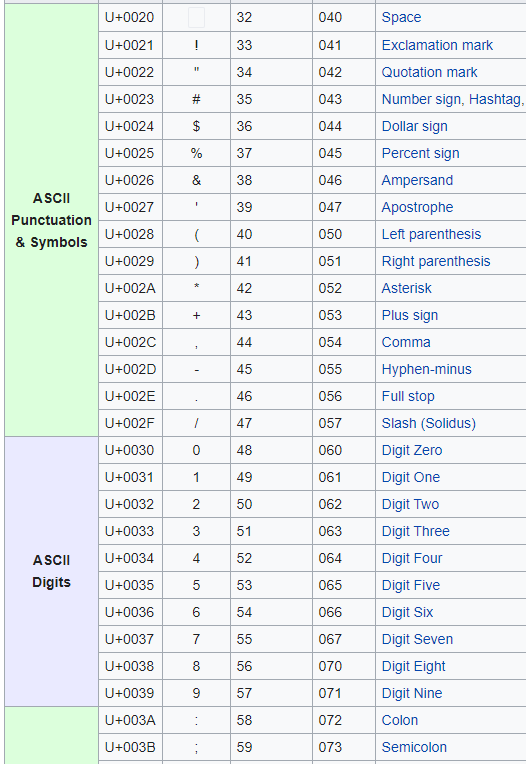
The code to remove everything except numbers is
Text.Remove([Text], {" ".."/", ":".."~"} )
Summary
So that's how to use Text.Select and Text.Remove.
I should say that I'm working with standard English Unicode set. You may be using an extended character set depending on your language and/or locale.
Best of luck cleaning up those messy strings.


Hi I try and add = Table.AddColumn(#”Added Custom1″, “Custom”, each Text.Select([Total Attendees], {“0”..”9″})) but I get an error saying it can’t change the type to text in the added column.
Expression.Error: We cannot convert the value 18 to type Text.
Details:
Value=18
Type=[Type]
[Total Attendees] is an option of some number and also had “NA” in there.
Hi Sara,
Can you upload a sample file replicating the error on our forum (create a new topic)?
Thank you
Is it allowed to nest text. functions? I’ve got a text field [Event Title] that contains alphas and numbers BUT should also include a parenthetical (which describes the number of cases expected). Like this:
AlphasNumbersAlphas (Numbers Alphas)
I want to snatch the parenthetical AND THEN grab the numbers from there. Here is my code:
= Table.AddColumn(#”Changed Type1″, “Cases expected”, each
Text.Select
(Text.BetweenDelimiters([Event Title], “(“, “)” ),
{“0”..”9″}, type text)
)
The inner function grabs the parenthetical, then the outer function should grab the number from the inner function. I feel like I’ve either got a close paren in the wrong place or else this idea simply is not allowed. Help?
Hi Brian,
So if you have this
Asdf2345BAXZ (1212 zxcv)
You want this
1212
??
If so then this works
= Text.Select(Text.BetweenDelimiters([Event Title], “(“, “)” ),{“0”..”9″})
If you’re still having issues please post the qs on our forum along with your file.
regards
Phil
Yes!! That “type text” was indeed the bug in my code. Your solution is perfect, thank you!
no worries.
Hi, I Need Help
I will do function who remove text in different two tables
Please post your question on our Excel forum where you can also upload a sample file and we can help you further.
Example Text: “Do you know DF1234 is our case number?” or “Our Case number is (DF1321)” or “DF2453: This is the case number”
Trying to extract the case number from the Text. The case always has DF and is followed by 4 Numbers.
Please help
Hi Tommy,
You could create a custom column using this
Download this example workbook.
Regards
Phil
This was incredibly useful – thanks for that. I just wanted to add that my data had decimal numbers in text form – I was having a problem that my numbers were coming out as, for example, 123 instead of 1.23.
I managed to fix the issue by adding “.” into my Number.FromText query as in:
Number.FromText((Text.Select([COLUMN], {“0″..”9″,”.”})
I hope that’s useful for someone else – it took me a while to figure out.
Chris
Thanks for that Chris.
How do I extract a system number from a text string i.e “6B0643” from “Maintenance Plan – 6B0643 – Pallet Tank”?
Try:
= Table.TransformColumns(#”Changed Type”, {{“Column1”, each Text.BetweenDelimiters(_, “–”, “–”), type text}})
I have a text field with characters I want only ends with # (hastang)
Thanks.
Text.Select([message], {“#”..””}))
Hi Omar,
Not sure what you mean. Please post your question and sample Excel file on our forum where we can help you further and our answers can also help others: https://www.myonlinetraininghub.com/excel-forum
Mynda
Really interesting, and very useful, however can you advise what to use to replace 41h, 15m to show 41.15 removing text and replacing delimiter, i have tried all your examples but none actually meet this need.
Hi Dave,
=–Substitute(Substitute(“41h, 15m”, “h, “, “.”),”m”,””) should return 41.15 but please keep in mind that 41.15 is a decimal format, representing 41 and 15/100. 41h and 15 minutes is equal to 41 h and 15/60 minutes when converted from time system to decimal system, so the correct answer should be 41.25!
The correct formula should be:
=–LEFT(A2,FIND(“h”,A2)-1)+SUBSTITUTE(RIGHT(A2,LEN(A2)-FIND(” “,A2)),”m”,””)/60
Or, better:
=–SUBSTITUTE(SUBSTITUTE(A2, “h, “, “:”),”m”,””)*24
Please change “Text.Extract” to “Text.Remove” in title.
Thanks
Power Stuff !!!
Thanks Derek