Hi,
I've been looking at this method of finding text in a row that matches words from a separate list:
I have 3 questions:
1. How can it be modified to ignore case in the TextTable (as well as the WordList)?
2. How can it be modified to accommodate a null value in the TextCol without producing the Expression.Error: We cannot convert the value null to type Logical.
3. How could we get the added custom column to return a value looked-up from a column next to the word matched in the WordList (for example to allow it to correct typos/mis-spellings, etc.)?
Like in the picture below (based on Phil's example spreadsheet):


Hi KS,
To ignore case in the TextTable you can make the text and the words you're searching for all the same case by using either Text.Lower or Text.Upper e.g.
if Text.Contains(Text.Lower([TextCol]), Text.Lower(current))
To prevent errors with null strings wrap the code in try .. otherwise e.g.
try if Text.Contains(Text.Lower([TextCol]), Text.Lower(current))
then state & " " & current
else state
otherwise null
You can change the value after otherwise to some other value if you like, I've just used null
More on try..otherwise -> Error handling in Power Query with try Otherwise
For the 3rd question, we'll be loading a table with 2 columns
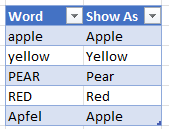
I've called this table WordList2
In the query you need to change the list that List.Accumulate uses like this, where the Word column is explicitly referred to
each List.Accumulate
(
WordList2[Word],
"",
then in the code, rather than concatenate state and current, use the position of current in the [Word] column to pick out the corresponding word you want to return instead from the [Show As] column
try if Text.Contains(Text.Lower([TextCol]), Text.Lower(current))
then state & " " & WordList2[Show As]{List.PositionOf(WordList2[Word], current)}
else state
otherwise null
Giving this
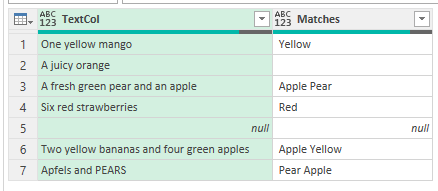
You can download the file with this code in it here
Regards
Phil
Phil,
Thanks a lot for taking the time to explain the modifications (and 'try' 'otherwise').
That approach is much more efficient than the route I had tried before here (which loads the WordList table, expands against an index, adds a conditional column, then removes nulls and re-merges), requiring a lot more steps.
To remove the leading space before the first matched word or where there is only one matched word, I added:
Text.Trim(state & " " & WordList2[Show As]{List.PositionOf(WordList2[Word], current)})
In my actual file (37k rows x 20 columns), I used this approach to create 3 columns. For the first added column the lookup table is only 3 rows x 2 columns [Word], [Show As] . The next 2 added columns use a lookup table that has 18 rows.
When I open the query, all the columns load within a few seconds, but when I 'Close and Load' to 'connection only' and check 'add to data model' it takes more than 30 minutes to load all 37k rows, whereas surprisingly using the more long-winded merge approach in the linked video, the rows load as a connection only in about 90 seconds.
I was able to resolve it (I think), by buffering the tables after 'let' & before 'source'
BufferedList2= Table.Buffer(WordList2)
and then using that reference in the later M code, e.g.
Text.Trim(state & " " & BufferedList2[Show As]{List.PositionOf(BufferedList2[Word], current)})
Is that the best way to do it, or is there a better / more efficient way?
Hi KS,
No worries.
Yes using Table.Buffer and List.Buffer are the way I'd do it too, it makes PQ much faster.
Regards
Phil