Hello,
I want to update a table 'Data_Table' based on data from a second source 'Platform_Data' (which is a query from a csv file).
I created a power query who's source is 'Data_Table', added some Replacer.ReplaceValue operations for some of the columns and now want to load the results back to the original table 'Data_Table', but Excel says "Query results cannot overlap a table or XML mapping. Please select another destination".
I don't want create a second, new table somewhere.
What am I doing wrong?
(Also posted here: https://www.mrexcel.com/board/threads/power-query-update-source-table.1231381 )

Hi k s,
You can't load a PQ transformed table back on top of the original source table. The whole idea with PQ is that you connect to a source and create some extract/analysis without touching the source and load it back to Excel or perhaps the Data Model.
R
Thanks for your reply,
How would you go about updating a table in this scenario ?
e.g. I have table of records ('Data_Table') by customer from which I'm going to make a sales dashboard which contains some basic data like address, city, etc, and some calculated columns/fields. Some of these fields may be updated in another system which produces an overnight csv file, which I bring into Excel using power query ('Updated_data') and compare with the excel table. If anything is newer or meets certain conditions in 'Updated_data' in , I want my excel 'Data_Table' table to be updated with the new information.
Isn't this exactly what power query is for?
Perhaps I just don't understand your intentions or the work-flow you are describing. I thought you were suggesting to update the original source with the output of PQ.
Perhaps the attached file is something you can use. It uses a technique where you connect to a PQ output table and to a table with new information. Then you append the two and eliminate duplicates and do some sorting. I created the example a while ago for someone who want to build an historic price-list, by having an old list and adding updated prices.
If I've missed the point completely, you can perhaps upload a file that demonstrates the issue you are dealing with.
Thanks for your reply
I've attached a file with an example / explanation that looks like the image below.
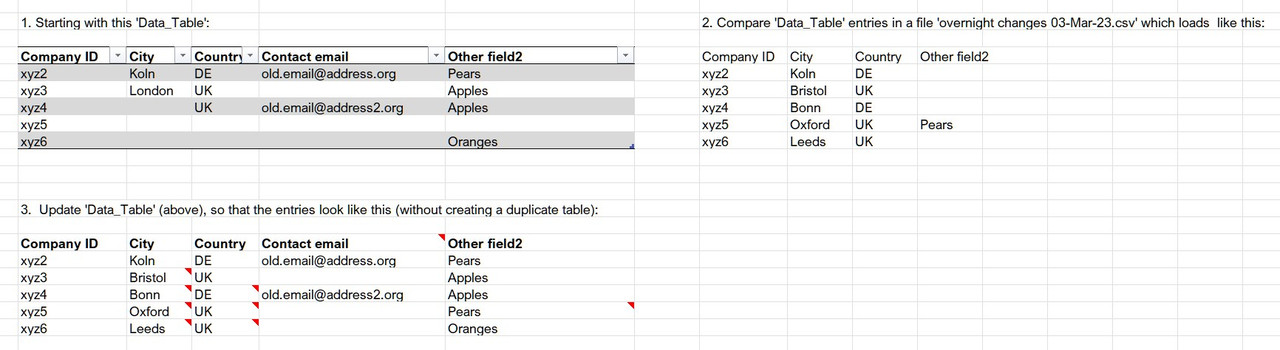
In reality my 'Data_Table' table has 135 columns (many calculated and/or constrained data-validated with lists in other tables) x ~10,000 rows, and is the source of several pivot tables, which is why I want to avoid creating a duplicate of the original table.
I want to update 15 of the columns where there are gaps or newer data in the overnight csv file, but only those columns.
Does that make sense?
Thanks for the file. That helped. The attached file contains a working solution.
I created some intermediate steps and helper queries that perhaps can be integrated into something fancier. But, I believe this was easier to follow and debug.
It's based on the principle of a self referencing table, similar to what I demonstrated in the file with my previous post. Though, your example is more complicated as I understood that the Updates table may vary each time. It will have a column for the company ID followed by the columns that contain changes. And I assumed that not every company in the Data_Table will be in the Updates every time. That's why I added some extra companies to test the concept. As said, I believe this works, though I can't predict how this will perform on a much larger scale.
See if you can get it to work and let me know.
Many thanks for putting the time into trying to create a solution. I've been looking at the file and trying to work out what it's doing
It seems creating Data_Table_2 is an interim / temporary step. Presumably it is made by first creating a query from Data_Table? Does it need to be loaded to a second table on a worksheet or can it be a connection only?
Then the Data_Table query actually uses Data_Table_2 as its source.
The we get into removing column names.
I'm not really sure why / what the logic is.
It seems we're keeping a list in the 'ColNames_kept' query which currently keeps the Company ID and email address. I guess that's the unique identifier plus the column name(s) present in the CSV. But these are the ones removed (i.e. not kept) in the Data_Table query.
Then we merge in the CSV data but instead of expanding the data, that column (Updates) is removed. I'm not sure why?
Then we append Updates and another query Data_Table_kept.
Data_Table_kept appears to use Data_Table_2 as its source. I don't really understand what its doing. It seems to retain only the columns in ColNames_kept query (as above)
Then back in the Data_Table query we
- group the rows by Company ID
- do a Table.FillDown which I don't really understand
- do a Table.RemoveFirstN which I don't really understand
- keep only that last column and expand, sort and re-order it into what appears to be the final Data_Table_2
I don't understand how that then updates the original Data_Table
You raise many questions that aren't easily explained. I'm really sorry for that. But regarding you very last comment "how that then updates the original Data_Table". It doesn't.
You start with an original Data_Table. Then you add updates to it and create a new Source for the next round of updates, but the original Data table is not used anymore. It's the Data_Table_2 that references itself when new updates come in.
I see I'm having difficulty to explain it.
Went back to my file and did some more tests and noticed that the queries don't pick-up new company ID's correctly. But it works for updates to existing queries. Obviously, you want to be able to add new records through the Updates table.
Yes, I'm afraid I don't get the approach.
Are you saying the original Data_Table is used only once as a way to set up the subsequently used Data_Table_2, then any updates from the overnight csv (Updates query) get subsequently added to Data_Table_2?
If so, can I prevent the formulae any in calculated columns in Data_Table_2 from being overwritten?
I'm afraid your particular situation isn't suitable for PQ then. Unless I'm wrong. In that case I'll leave it to someone else to resolve, Sorry.